This guide is designed to help you understand the capabilities included in Snowflake's support for Apache Iceberg. Iceberg Tables, now generally available, bring Snowflake's easy platform management and great performance to data stored externally in the open source Apache Iceberg format.
Key Aspects of Table Format
- Organizing data in rows and columns, using optimized file formats like Parquet, ORC, or Avro.
- Manage metadata (schema, partitions, file locations, version history).
- Support partitioning to improve query performance.
- Support ACID transactions for reliability.
- Schema evolution for flexible updates.
- Data versioning for historical data queries or time travel.
- Table formats are scalable, designed for large datasets in distributed storage systems such as HDFS or cloud storage.
- Efficient storage and analytical queries. Efficient querying by engines like Spark or Hive.
- Major types of table formats used in big data analytics and data lakes - Apache Iceberg, Apache Hudi, Delta Lake.
Snowflake's support for Apache Iceberg
- An Iceberg table uses the Apache Iceberg open table format specification.
- They are ideal for existing data lakes that you cannot, or choose not to, store in Snowflake.
- Iceberg tables for Snowflake combine the performance and query semantics of regular Snowflake tables with external cloud storage.
- Snowflake supports Iceberg tables that use the Apache Parquet file format.
Prerequisites
- Familiarity with Snowflake
- Familiarity with cloud object storage
- Familiarity with SQL
- Familiarity with Apache Iceberg
What You'll Learn
- How to create a Snowflake-managed Iceberg Table
- How to share an Iceberg Table
- How to apply Cortex LLM Functions on an Iceberg Table
- How to apply governance policies on an Iceberg Table
- How Snowpark can be used for Iceberg Table pipelines
- How to access a Snowflake-managed Iceberg Table from Apache Spark
What You'll Need
- A Snowflake account. A free trial will suffice. Standard Edition will work for most of this lab, but if you'd like to try governance features covered in section 4, you will need Enterprise or Business Critical Edition.
- A storage bucket with the same cloud provider in the same region that hosts your Snowflake account above. Direct credential access required as storage integrations are not supported for External Volumes.
What You'll Build
- A simple, open data lakehouse with Snowflake, Iceberg, and your cloud of choice
Setup Snowflake
Create a database, schema, warehouse, role, and user called ICEBERG_LAB in your Snowflake account.
CREATE WAREHOUSE iceberg_lab;
CREATE ROLE iceberg_lab;
CREATE DATABASE iceberg_lab;
CREATE SCHEMA iceberg_lab;
GRANT ALL ON DATABASE iceberg_lab TO ROLE iceberg_lab WITH GRANT OPTION;
GRANT ALL ON SCHEMA iceberg_lab.iceberg_lab TO ROLE iceberg_lab WITH GRANT OPTION;;
GRANT ALL ON WAREHOUSE iceberg_lab TO ROLE iceberg_lab WITH GRANT OPTION;;
CREATE USER iceberg_lab
PASSWORD='<your desired password>',
LOGIN_NAME='ICEBERG_LAB',
MUST_CHANGE_PASSWORD=FALSE,
DISABLED=FALSE,
DEFAULT_WAREHOUSE='ICEBERG_LAB',
DEFAULT_NAMESPACE='ICEBERG_LAB.ICEBERG_LAB',
DEFAULT_ROLE='ICEBERG_LAB';
GRANT ROLE iceberg_lab TO USER iceberg_lab;
GRANT ROLE iceberg_lab TO USER <your username>;
GRANT ROLE accountadmin TO USER iceberg_lab;
Create an External Volume
Before you create an Iceberg table, you must have an external volume. An external volume is a Snowflake object that stores information about your cloud storage locations and identity and access management (IAM) entities (for example, IAM roles). Snowflake uses an external volume to establish a connection with your cloud storage in order to access Iceberg metadata and Parquet data.
To create an external volume, complete the instructions for your cloud storage service:
- Accessing Amazon S3 using external volumes
- Accessing Google Cloud Storage using external volumes
- Accessing Microsoft Azure Storage using external volumes
- BlueCloud Iceberg Tables
Create a Snowflake-managed Iceberg Table
Iceberg Tables can either use Snowflake, AWS Glue, or object storage as the catalog. In this quickstart, we use Snowflake as the catalog to allow read and write operations to tables. More information about integrating catalogs can be found here.
Create an Iceberg Table referencing the external volume you just created. You can specify BASE_LOCATION to instruct Snowflake where to write table data and metadata, or leave empty to write data and metadata to the location specified in the external volume definition.
A catalog integration is a named, account-level Snowflake object that stores information about how your table metadata is organized. Iceberg Tables can either use Snowflake, AWS Glue, or object storage as the catalog. In this demo, we use Snowflake as the catalog to allow read and write operations to tables.
-- Use the ACCOUNTADMIN role to grant usage to the ICEBERG_LAB role.
USE ROLE ACCOUNTADMIN;
GRANT ALL ON EXTERNAL VOLUME iceberg_lab_vol TO ROLE iceberg_lab WITH GRANT OPTION;
USE ROLE iceberg_lab;
USE DATABASE iceberg_lab;
USE SCHEMA iceberg_lab;
USE WAREHOUSE iceberg_lab;
-- Create Iceberg Table
CREATE OR REPLACE ICEBERG TABLE customer_iceberg (
date_created date,
language string,
country string,
product string,
category string,
damage_type string,
transcript string
)
CATALOG='SNOWFLAKE'
EXTERNAL_VOLUME='iceberg_lab_vol'
BASE_LOCATION='';
Load Data
There are multiple ways to load new data into Snowflake-managed Iceberg Tables including INSERT, COPY INTO, and Snowpipe.
For this quickstart, we will INSERT data from the sample tables in your Snowflake account to an Iceberg Table. This will write Parquet files and Iceberg metadata to your external volume.
-- Set Up The Ski Store Dataset
-- Create file format
CREATE or REPLACE file format csvformat
SKIP_HEADER = 1
FIELD_OPTIONALLY_ENCLOSED_BY = '"'
type = 'CSV';
-- Create stage
CREATE or REPLACE stage call_transcripts_data_stage
file_format = csvformat
url = 's3://sfquickstarts/misc/call_transcripts/';
-- Create table
CREATE or REPLACE table CALL_TRANSCRIPTS (
date_created date,
language varchar(60),
country varchar(60),
product varchar(60),
category varchar(60),
damage_type varchar(90),
transcript varchar);
-- Load data to CALL_TRANSCRIPTS table
COPY into CALL_TRANSCRIPTS from @call_transcripts_data_stage;
-- Load the CALL_TRANSCRIPTS data to Iceberg table
-- Load data into Iceberg table
INSERT INTO customer_iceberg
SELECT * FROM CALL_TRANSCRIPTS;
-- Check the data loaded
SELECT * FROM customer_iceberg;
If you check your cloud storage bucket, you should now see files that Snowflake has written as part of table creation. While Snowflake writes these files automatically, you can also use a function to generate table metadata files that capture any data manipulation language (DML) changes that have been made since the last time Iceberg metadata was generated.
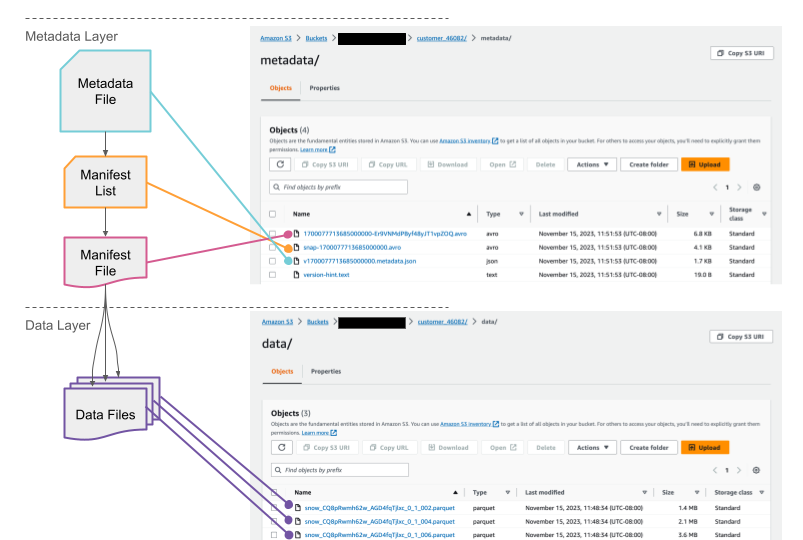
Query and Time Travel
Iceberg Tables are treated much like other tables in Snowflake.
SELECT *
FROM customer_iceberg c;
ALTER ICEBERG TABLE customer_iceberg ADD COLUMN c_nationkey NUMBER(38,0 );
Benefits of the additional metadata that table formats like Iceberg and Snowflake's provide are, for example, time travel.
Let's make few updates to the data in the table. Then, you can see that data in the c_nationkey column has changed compared to the previous version.
UPDATE customer_iceberg SET COUNTRY = 'US' WHERE COUNTRY = 'Germany';
UPDATE customer_iceberg SET c_nationkey = 24 WHERE COUNTRY = 'US';
UPDATE customer_iceberg SET c_nationkey = 20 WHERE COUNTRY <> 'US';
SELECT c_nationkey, * FROM customer_iceberg
BEFORE(statement => LAST_QUERY_ID());
Iceberg Tables can be securely shared with consumers either through their own Snowflake account or a provisioned Snowflake Reader account. The consumer can be an external entity or a different internal business unit that is required to have its own unique Snowflake account.
With data sharing, including Iceberg Tables:
- There is only one copy of the data that's stored in the data provider's cloud storage account.
- The latest snapshot available in the producer account is always live, real-time, and immediately available to consumers.
- Providers can establish revocable, fine-grained access to shares.
- Data sharing is simple and safe, especially compared to older data sharing methods, which were often manual and insecure, such as transferring large .csv files across the internet.
Suppose you have a partner who wants to analyze the data in your ICEBERG_LAB database on a near real-time basis. This partner also has their own Snowflake account in the same region as our account. Data sharing is an easy, secure solution to allow them to access this information.
Creating a Reader Account
For the purposes of this lab, we'll share data with a provisioned reader account. Return to your SQL worksheet, and grant the ICEBERG_LAB role the ability to create a reader account.
USE ROLE accountadmin;
GRANT CREATE ACCOUNT ON ACCOUNT TO ROLE iceberg_lab;
USE ROLE ICEBERG_LAB;
Exit your SQL worksheet and navigate to Private Sharing, then click the tab Reader Accounts near the top of your window, then click + New. Use ICEBERG_LAB_READER as the Account Name, READER_ADMIN as the User Name, and provide a password. Then click Create Account. You'll see the reader account now listed.
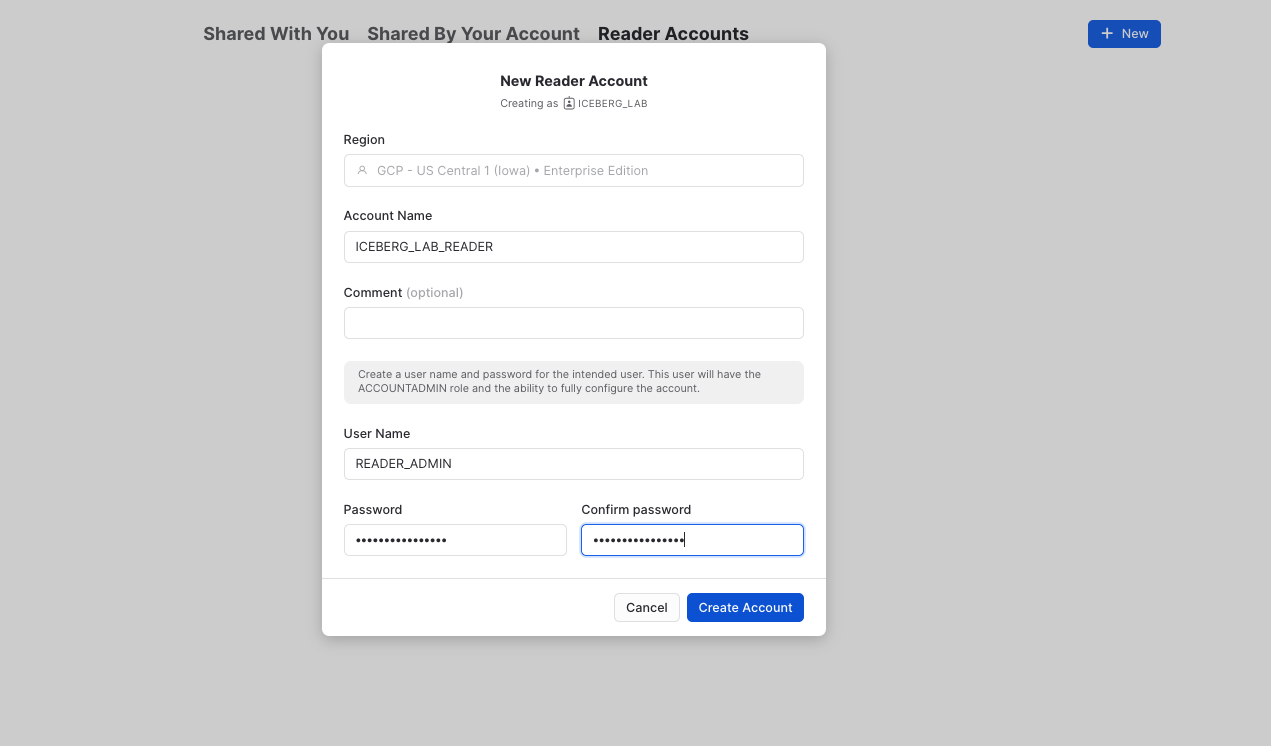
The Iceberg Table (customer_iceberg) will be shared with the ICEBERG_LAB_READER account.
Create an Outbound Share
By default, ACCOUNTADMIN is the only role that can create shares. From your SQL worksheet, grant the ICEBERG_LAB role to create a share, then use this role.
USE ROLE accountadmin;
GRANT CREATE SHARE ON ACCOUNT TO ROLE iceberg_lab;
USE ROLE iceberg_lab;
Exit the SQL worksheet and navigate to Data » Private Sharing, then click on the Shared by My Account tab near the top of your window, then click the Share button in the top-right corner and select Create a Direct Share.
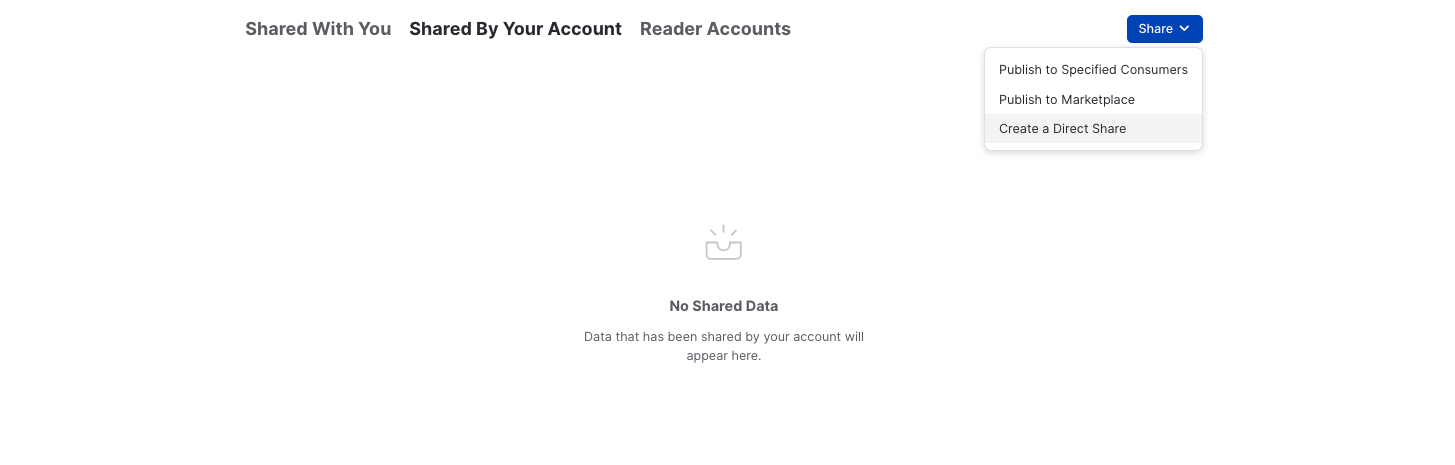
Click + Select Data and navigate to the ICEBERG_LAB database and schema. Select the customer_iceberg table you created in the schema and click the Done button. Edit the default name to a more descriptive value that will help identify the share in the future (e.g. ICEBERG_LAB_CUSTOMER_ICEBERG_SHARED_DATA). You can also add a comment.
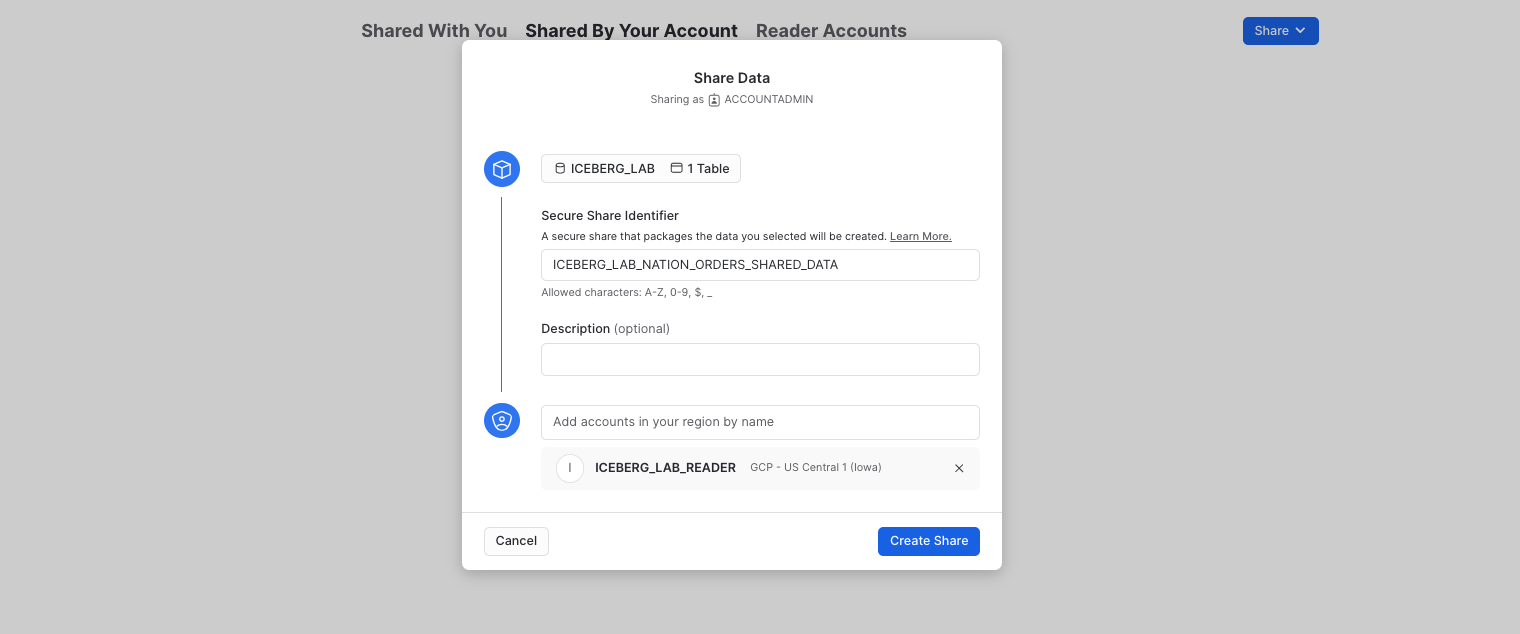
Accessing Shared Data
In a separate browser tab, login to the reader account previously created. After logging in, as this is a new account, create a new SQL worksheet..
USE ROLE accountadmin;
CREATE WAREHOUSE IF NOT EXISTS iceberg_lab_reader
WAREHOUSE_SIZE = XSMALL
AUTO_SUSPEND = 1
INITIALLY_SUSPENDED = TRUE;
Now let's view the shared data. Exit the worksheet, and in the pane on the left, click on on Data » Private Sharing. You will see ICEBERG_LAB_CUSTOMER_ICEBERG_SHARED_DATA listed under Direct Shares. Select Get Data and name it READER_ICEBERG_LAB_CUSTOMER_ICEBERG_SHARED_DATA. Make it available to the PUBLIC role, then click Get Data, then click View Database.
You can now query the shared data.
SELECT * FROM READER_ICEBERG_LAB_CUSTOMER_ICEBERG_SHARED_DATA.ICEBERG_LAB.CUSTOMER_ICEBERG;
As changes are made to the Iceberg Table from the producer's account, those changes are available nearly instantly in the reader account. No copying or transferring of data required! The single copy of data is stored in your cloud storage.
Snowflake Cortex gives you instant access to industry-leading large language models (LLMs) trained by researchers at companies like Mistral, Reka, Meta, and Google, including Snowflake Arctic, an open enterprise-grade model developed by Snowflake.
Since these LLMs are fully hosted and managed by Snowflake, using them requires no setup. Your data stays within Snowflake, giving you the performance, scalability, and governance you expect. Snowflake Cortex features are provided as SQL functions and are also available in Python.
-- TRANSLATE: Translates given text from any supported language to any other.
-- English to German
SELECT SNOWFLAKE.CORTEX.TRANSLATE(TRANSCRIPT, 'en', 'de') FROM CUSTOMER_ICEBERG LIMIT 5;
-- SUMMARIZE: Returns a summary of the given text.
SELECT SNOWFLAKE.CORTEX.SUMMARIZE(TRANSCRIPT) FROM CUSTOMER_ICEBERG LIMIT 5;
-- SENTIMENT: Returns a sentiment score, from -1 to 1, representing the detected positive or negative sentiment of the given text.
SELECT SNOWFLAKE.CORTEX.SENTIMENT(TRANSCRIPT), TRANSCRIPT FROM CUSTOMER_ICEBERG LIMIT 5;
Governance and access controls work on Iceberg Tables just like internal tables. As described in the overview section, all of these features require Enterprise or Business Critical Edition of Snowflake.
Row-level Security
Suppose you need to control row-level access to an Iceberg Table for users having different roles. In this example, let's have a role that can see the US Customers and one that only sees the Non US Customers.
This can be done with a row access policy on the Iceberg Table.
USE ROLE accountadmin;
-- Role to see US Customers
CREATE OR REPLACE ROLE tpch_us;
GRANT ROLE tpch_us TO USER <your username>;
-- Role to see Non US Customers
CREATE OR REPLACE ROLE tpch_intl;
GRANT ROLE tpch_intl TO USER <your username>;
USE ROLE iceberg_lab;
-- Create Row access policy
CREATE OR REPLACE ROW ACCESS POLICY rap_nation
AS (nation_key number) RETURNS BOOLEAN ->
('TPCH_US' = current_role() and nation_key = 24) OR
('ICEBERG_LAB' = current_role() ) OR
('TPCH_INTL' = current_role() and nation_key != 24);
SELECT COUNT(1) as count, c_nationkey FROM customer_iceberg GROUP BY c_nationkey;
-- Output:
-- COUNT C_NATIONKEY
-- 85 24 >>> (US Customers)
-- 115 20 >>> (Non US Customers)
USE ROLE accountadmin;
-- Add row access policy to table
ALTER ICEBERG TABLE customer_iceberg
ADD ROW ACCESS POLICY rap_nation ON (c_nationkey);
GRANT ALL ON DATABASE iceberg_lab TO ROLE tpch_intl;
GRANT ALL ON SCHEMA iceberg_lab.iceberg_lab TO ROLE tpch_intl;
GRANT ALL ON ICEBERG TABLE iceberg_lab.iceberg_lab.customer_iceberg TO ROLE tpch_intl;
GRANT ALL ON DATABASE iceberg_lab TO ROLE tpch_us;
GRANT ALL ON SCHEMA iceberg_lab.iceberg_lab TO ROLE tpch_us;
GRANT ALL ON ICEBERG TABLE iceberg_lab.iceberg_lab.customer_iceberg TO ROLE tpch_us;
GRANT USAGE ON EXTERNAL VOLUME iceberg_lab_vol TO ROLE tpch_intl;
GRANT USAGE ON EXTERNAL VOLUME iceberg_lab_vol TO ROLE tpch_us;
GRANT USAGE ON WAREHOUSE iceberg_lab TO ROLE tpch_us;
GRANT USAGE ON WAREHOUSE iceberg_lab TO ROLE tpch_intl;
There are two separate roles to grant to Snowflake users, which allow them to see a subset of customers, either US or Non US.
-- role = tpch_intl, Non US Customers
USE ROLE tpch_intl;
USE WAREHOUSE iceberg_lab;
SELECT COUNT(1) as count, c_nationkey FROM customer_iceberg GROUP BY c_nationkey;
-- Output:
-- COUNT C_NATIONKEY
-- 115 20
-- role = tpch_us, US Customers
USE ROLE tpch_us;
USE WAREHOUSE iceberg_lab;
SELECT COUNT(1) as count, c_nationkey FROM customer_iceberg GROUP BY c_nationkey;
-- Output:
-- COUNT C_NATIONKEY
-- 85 24
Column-level Security
We want the team of analysts to be able to query the customer_iceberg table but not see data in category column. To do so, we need to grant them access to all the rows but mask those specific fields.
We can do that with a masking policy.
USE ROLE accountadmin;
-- create new role - tpch_analyst
CREATE OR REPLACE ROLE tpch_analyst;
GRANT ROLE tpch_analyst TO USER <your username>;
USE ROLE iceberg_lab;
ALTER ROW ACCESS POLICY rap_nation
SET body ->
('TPCH_US' = current_role() and nation_key = 24) or
('TPCH_INTL' = current_role() and nation_key != 24) or
('TPCH_ANALYST' = current_role()) or
('ICEBERG_LAB' = current_role())
;
-- SET -> Specifies one (or more) properties to set for the row access policy:
-- BODY -> expression_on_arg_name. SQL expression that filters the data.
USE ROLE accountadmin;
GRANT ALL ON DATABASE iceberg_lab TO ROLE tpch_analyst;
GRANT ALL ON SCHEMA iceberg_lab.iceberg_lab TO ROLE tpch_analyst;
GRANT ALL ON TABLE iceberg_lab.iceberg_lab.customer_iceberg TO ROLE tpch_analyst;
GRANT USAGE ON WAREHOUSE iceberg_lab TO ROLE tpch_analyst;
GRANT USAGE ON EXTERNAL VOLUME iceberg_lab_vol TO ROLE tpch_analyst;
USE ROLE iceberg_lab;
-- create a masking policy
CREATE OR REPLACE MASKING POLICY pii_mask AS (val string) RETURNS string ->
CASE
WHEN 'TPCH_ANALYST' = current_role() THEN '*********'
ELSE val
END;
-- apply the masking policy to category column
ALTER ICEBERG TABLE customer_iceberg MODIFY COLUMN CATEGORY SET MASKING POLICY pii_mask;
-- when role = tpch_analyst, category column data should be masked
USE ROLE tpch_analyst;
SELECT * FROM customer_iceberg LIMIT 5;
-- when role = tpch_us, category column data should NOT be masked
USE ROLE tpch_us;
SELECT * FROM customer_iceberg LIMIT 5;
Other governance features can be applied to Iceberg Tables, including object tagging, and tag-based masking.
Monitor Governance in Snowsight
As a data administrator, you can use the built-in Dashboard and Tagged Objects interfaces to monitor and report on the usage of policies and tags with tables, views, and columns. This includes policies and tags applied to Iceberg Tables.
Using the ACCOUNTADMIN role, or an account role that is granted the GOVERNANCE_VIEWER and OBJECT_VIEWER database roles, click Data » Governance to navigate to these interfaces. You can see the policies applied to the Iceberg Table.
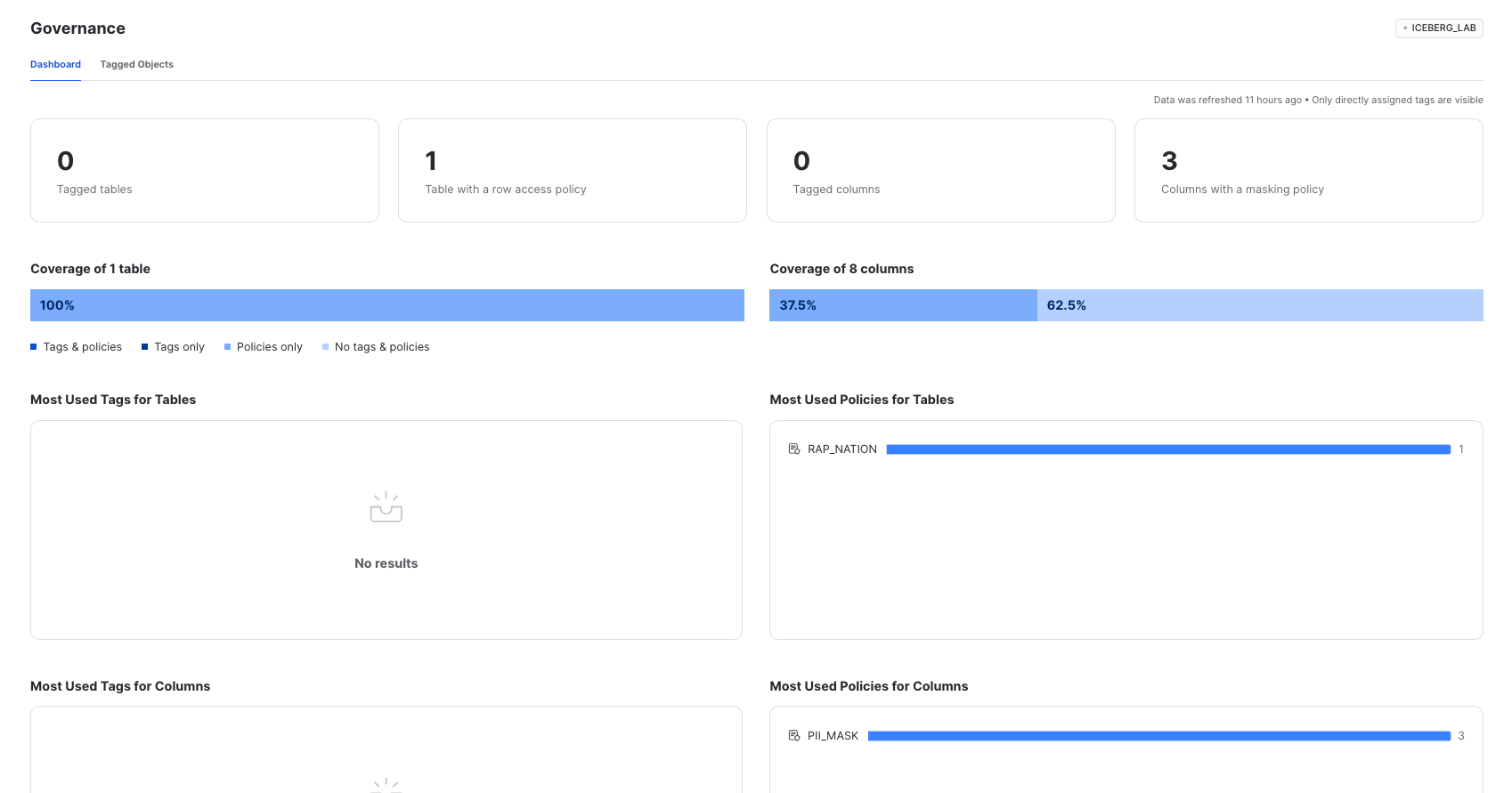
And if you notice certain tables are missing tags or policies, you can modify, create, and apply them directly from the interface.
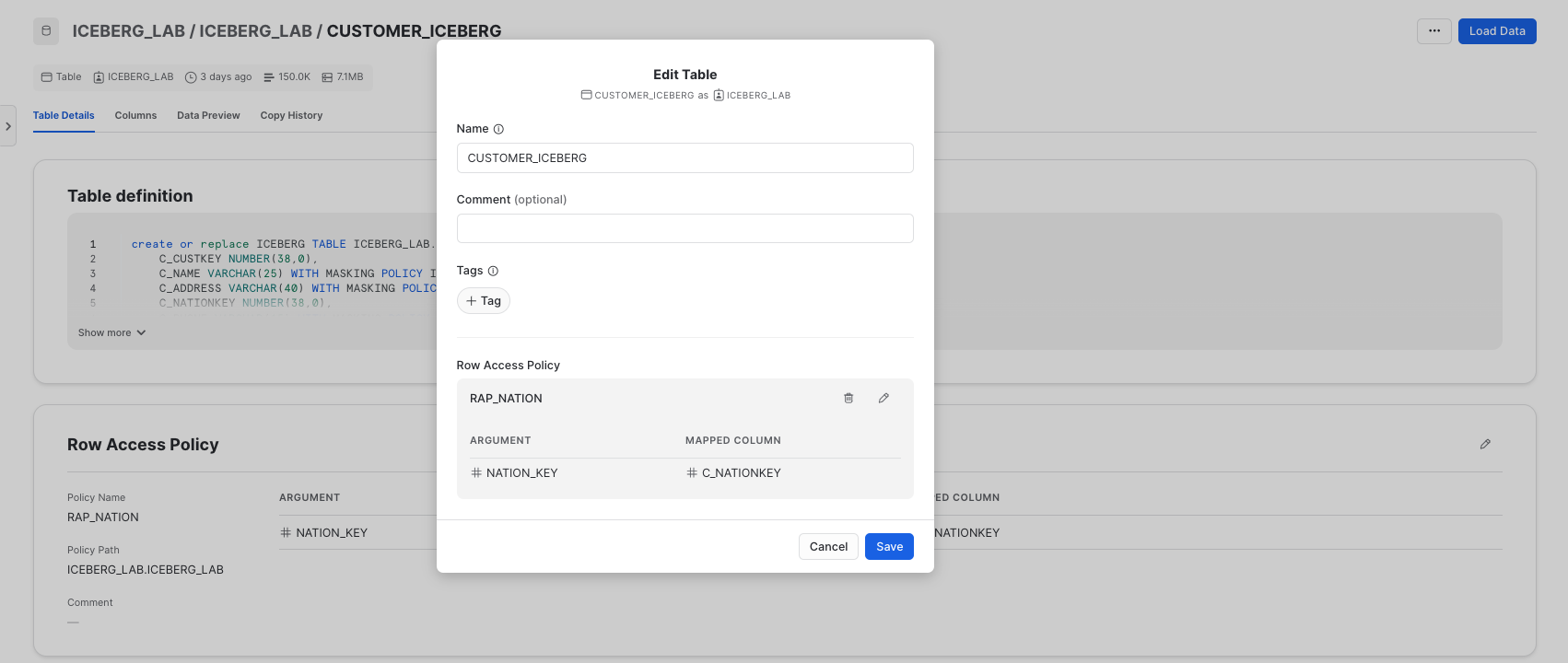
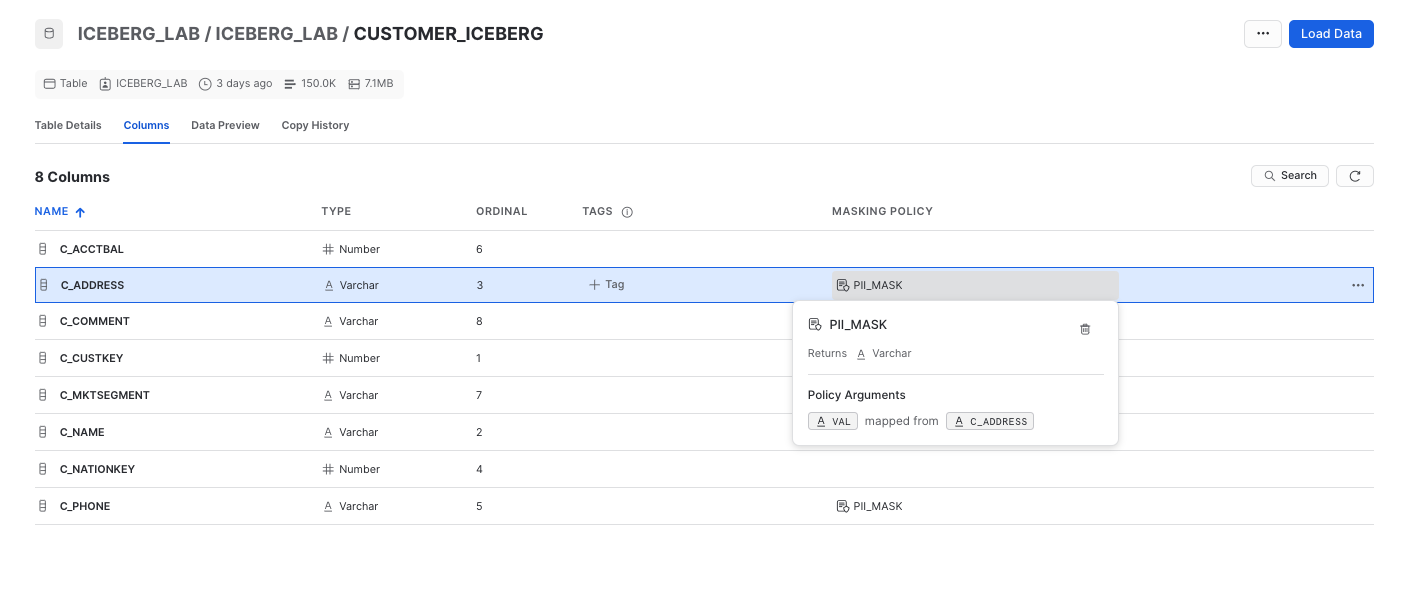
Snowpark is a set of libraries and runtimes in Snowflake that securely deploy and process non-SQL code, including Python, Java and Scala. Snowpark can be used for data science and data engineering pipelines, with key benefits including:
- Support for pushdown for all operations, leaving heavy lifting up to Snowflake and allowing you to efficiently work with data of any size.
- All of the computations are done within Snowflake – no separate cluster provision, scale, and secure.
You can interact with Iceberg Tables using DataFrames that are lazily executed. Let's try this by first creating an empty Iceberg table.
USE ROLE iceberg_lab;
USE DATABASE iceberg_lab;
USE SCHEMA iceberg_lab;
USE WAREHOUSE iceberg_lab;
-- Create Iceberg Table
CREATE OR REPLACE ICEBERG TABLE customer_iceberg_new (
date_created date,
language string,
country string,
product string,
category string,
damage_type string,
transcript string
)
CATALOG='SNOWFLAKE'
EXTERNAL_VOLUME='iceberg_lab_vol'
BASE_LOCATION='';
Create a new Python worksheet. Ensure ICEBERG_LAB role and warehouse are selected in the top-right, and ICEBERG_LAB database and schema are selected in your worksheet. After running the worksheet, you will see the data that was saved to the customer_iceberg_new table.
import snowflake.snowpark as snowpark
from snowflake.snowpark import functions as sf
def main(session: snowpark.Session):
# Create a DataFrame representing the 'CUSTOMER_ICEBERG' table
df_customer = session.read.table("ICEBERG_LAB.ICEBERG_LAB.CUSTOMER_ICEBERG")
df_customer_new = df_customer.select("date_created", "language", "country", "product", "category", "damage_type", "transcript",)
# Save result to the newly created iceberg table - customer_iceberg_new
df_customer_new.write.mode("append").save_as_table("customer_iceberg_new")
# Create a DataFrame representing the 'CUSTOMER_ICEBERG_NEW' table
df_customer_new_data = session.read.table("ICEBERG_LAB.ICEBERG_LAB.CUSTOMER_ICEBERG_NEW")
return df_customer_new_data
Suppose another team that uses Spark wants to read the Snowflake-managed Iceberg Table using their Spark clusters. They can use the Snowflake Iceberg Catalog SDK to access snapshot information, and directly access data and metadata in object storage, all without using any Snowflake warehouses.
To delete all of the objects created in this guide, you can drop the user, role, database, and warehouse.
USE ROLE iceberg_lab;
DROP SHARE ICEBERG_LAB_CUSTOMER_ICEBERG_SHARED_DATA;
DROP DATABASE iceberg_lab;
USE ROLE accountadmin;
DROP EXTERNAL VOLUME iceberg_lab_vol;
DROP USER iceberg_lab;
DROP ROLE iceberg_lab;
DROP ROLE tpch_us;
DROP ROLE tpch_intl;
DROP ROLE tpch_analyst;
DROP WAREHOUSE iceberg_lab;
Congratulations! You've successfully created an open data lakehouse on Snowflake with Iceberg.
What You Learned
- How to create a Snowflake-managed Iceberg Table
- How to share an Iceberg Table
- How to apply Cortex LLM Functions on an Iceberg Table
- How to apply governance policies on an Iceberg Table
- How Snowpark can be used for Iceberg Table pipelines
- How to access a Snowflake-managed Iceberg Table from Apache Spark